
Real-Time Hand Motion Parameter Estimation with Feature Point Detection Using Kinect
2014-03-24 05:40ChunMingChangCheHaoChangandChungLinHuang
Chun-Ming Chang, Che-Hao Chang, and Chung-Lin Huang
Real-Time Hand Motion Parameter Estimation with Feature Point Detection Using Kinect
Chun-Ming Chang, Che-Hao Chang, and Chung-Lin Huang
——This paper presents a real-time Kinectbased hand pose estimation method. Different from model-based and appearance-based approaches, our approach retrieves continuous hand motion parameters in real time. First, the hand region is segmented from the depth image. Then, some specific feature points on the hand are located by the random forest classifier, and the relative displacements of these feature points are transformed to a rotation invariant feature vector. Finally, the system retrieves the hand joint parameters by applying the regression functions on the feature vectors. Experimental results are compared with the ground truth dataset obtained by a data glove to show the effectiveness of our approach. The effects of different distances and different rotation angles for the estimation accuracy are also evaluated.
Index Terms——Hand motion, Kinect, parameter estimation, random forest, regression function.
1. Introduction
Hand tracking has been applied in various human computer interface (HCI) designs, such as sign language recognition, augmented reality, and virtual reality. Two major applications are hand gesture recognition and three dimensional (3D) hand pose estimation. The former analyzes the hand shape and location to identify the hand gesture which can be applied to sign language understanding. The latter estimates the hand parameters such as joint angles of each finger and global orientation of the palm. The 3D hand pose estimation is quite a challenge due to the lack of sufficient information and self-occlusion. It may be applied to the virtual reality or the robotic arm control.
There are two main approaches, appearance-based and model-based, for the hand pose estimation. The appearance-based method establishes a large amount of hand models pre-stored in a database. These hand models are generated by a synthesized virtual hand or constructed from a real hand. One of the samples in the database that best matches the current observation is retrieved. Romeroet al.used local sensitivity hashing (LSH) to search the nearest neighborhood in a large database that contains over 100000 hand poses with HOG (histogram of oriented gradient) features for real-time operations[1]. Miyamotoet al.designed a tree structure classifier based on the typical hand poses and their variations[2].
The model-based method estimates the motion parameters based on the on-line construction of a 3D articulated hand model to fit the observations. By rendering the hand model with different parameters iteratively, the deviation between the hand model and real observation will be converged, and the hand parameters can be obtained. Gorceet al.proposed to minimize the objective function between the observation and the model using the quasi-Newton method[3]. The objective function is measured by the difference of the texture and shading information. Oikonomidiset al.utilized particle swarm optimization (PSO) to solve the optimization problem of matching process with a depth image[4],[5]. Hameret al.created a hand model with 16 separate segments connected in a pairwise Markov random field, and adjusted the states of segments by belief propagation based on both RGB (red, green, and blue) and depth images[6]. Some approaches evaluated the 3D human body joints and hand joints based on the depth sensors without markers[7],[8]. Similar to [8], we perform the feature transformation in our method to estimate the hand motion parameters in real time.
This paper proposes a new approach to estimate hand parameters by analyzing the depth maps and applying regression functions. First, the hand depth map is segmented. Then, we apply a pixel-based classification to categorize each pixel in the hand map into 9 classes which consist of 5 fingertips, 3 blocks on palm, and one for the rest part of hand. The classifier is developed by using a random forest classifier. We exact the feature points from the depth maps which are converted into feature space for regression functions. Based on the regression functions, the hand motion parameters can be obtained.
Our approach does not use gesture recognition or iterative approximation to develop real-time hand motion parameter estimation. Different from the method proposed by Pó?rola[8], we construct a reliable transform operation. The proposed method can retrieve the continuous hand motion parameters by using the regression functions with less computation load. The virtual hand gestures are reconstructed from the obtained parameters. They are compared with the ground truth dataset to show the accuracy of the estimated hand motion parameters.
2. Hand Extraction
To extract the hand features from a depth image, we take the following steps: a) remove the background which does not belong to a hand in the depth map, b) find the center of the hand and make it shift and rotation invariant, and c) resize the hand to achieve depth invariant.
We assume that a hand is the object closest to the depth sensor. The pixels within a specified distance on the depth image are considered to be the hand region. A threshold is applied to remove the non-hand object and disturbance.
To find the center of a hand, we apply the distance transform to the hand image and generate a gray-level image of which the gray scale value of each pixel indicates the distance to the closest boundary from itself. Finally, we compute the center of mass of the binary image, which is obtained by using a threshold, as the centroid of the hand segment. Fig. 1 demonstrates the hand extracting procedure.

Fig. 1. Centroid locating steps: (a) hand shape extraction, (b) distance transformation, and (c) threshold processing.
However, the method may fail for the self-occluded hand gestures such as “okay sign” or “victory sign”, as shown in Fig. 2. Some undefined depth blocks in the depth maps need to be resolved before applying the distance transformation. To deal with the self-occlusion problem, we dilate the hand silhouette to differentiate the un-defined blocks from the background. Then, a flood-fill operation is applied to remove these un-defined blocks inside the hand region. Finally, we erode the image to eliminate the effect of dilation done previously. This process can effectively remove the un-defined blocks within the hand region while locating the hand centroid.
Hand size is normalized to make it distance independent. Letdavgdenote the average of the segmented hand depth image. The hand size is rescaled by a constant which is proportional todavg.

Fig. 2. Resolving the self-occlusion problem: (a) original image and (b) distance-transformed image.
3. Finger Joint Locating
The selected features in our approach are the relative distances in the 3D space of specific feature points on a hand. To find these feature points, a robust positioning method is needed.
3.1 Per-Pixel Classification
Similar to [7] and [8], we apply a pixel-based classification method to handle the rotation case. However, a different split function which has been proved to be effective is used. Taking the rotation case (e.g., waving hands) into consideration, the split criterion is based on the feature function defined as

wherefu,v(I, x) is the feature function,dI(x) is the depth of x in imageI, and u and v are the offset vectors. The location of pixel x and the vectors u and v are in the polar coordinate. The centroid of the palm is the origin of polar coordinate system. With such feature function, the feature value remains the same after rotation since the relative position between x and its offset is rotation invariant, as shown in Fig. 3.
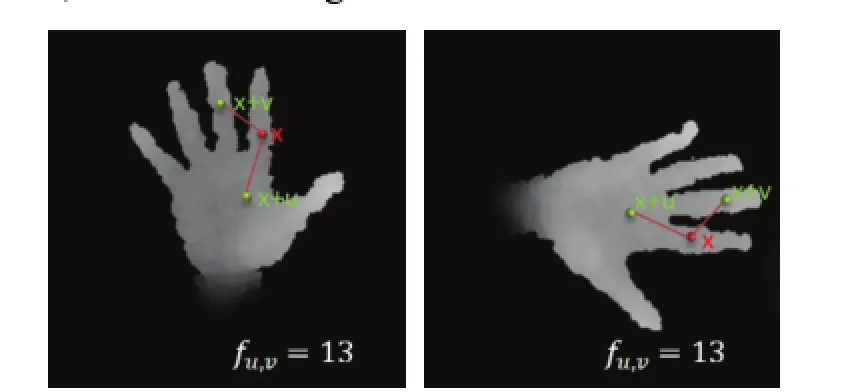
Fig. 3. Rotation-invariant feature function.
The per-pixel classification is done by the random forest in [7]. The training sample sets for decision tree training are randomly selected. Training samples are split into two groups by the split criterion:

whereτis a threshold. In the training process, a gain function is defined to measure the effectiveness of the split function based on different split node parameters?:

whereH(Q) is the Shannon entropy used to calculate the entropy of the normalized histogram. For each split node parameter,?=(θ,τ), we may separate the training sample set and compute the gain function. The larger the gain function, the better the split function. In the training process, the split node parameter?is randomly generated. The best split node parameter can be determined by
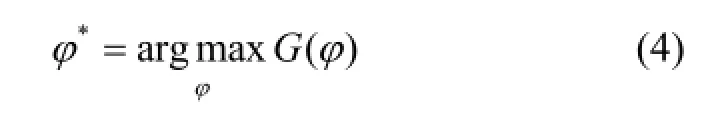
The two split nodes will be determined by two separated subsetsQLandQR. The split nodes will be generated iteratively until either of the following two conditions is met: 1) the number of the samples is not sufficient and 2) the entropy is too small, indicating that the most of the samples in the set are of the same class. Based on the labeled training samples in the leaf nodes, we may calculate the posteriori of each classCof thetth decision tree asPt(C|x).
3.2 Joint Locating
After the per-pixel classification, we obtain the probability distribution maps for each class. Next, we have to locate the center of each class except for the class that contains the rest part of the hand. A Gaussian kernel with an appropriate size (16×16 pixels) on the distribution maps is applied to find the maximum to the position of the feature points on a hand, as shown in Fig. 4.

Fig. 4. Feature point detection results: (a) labeled image. (b) detected feature points.
The results from the previous steps are the 2-D locations of feature points. The depth information of each feature point can be easily determined as

whereiis the class index,Gp(i)is a Gaussian mask centered on feature pointp(i),P(i) is the probability distribution map of classi, andIis the depth image.
4. Feature Vector Formation
We use the 3D feature point locations to estimate the hand motion parameters. The feature vector X is defined as

wherexis 3D location of the feature point anddis the depth value of the feature point. The feature points include five points at the fingertips (xthumb,xindex,xmiddle,xring,xlittle), one point at the palm center,xpalm_c, and two feature points nearby the palm center (xpalm_1,xpalm_2) that are chosen not occluded by the bending fingers.
5. Regression Function Training
The support vector machine (SVM) is a supervised learning model with associated algorithms that analyze data for classification and regression[9]. In classification, the training data is mapped into a hyper dimensional space, and a hyper plane will be constructed to separate the training data with the largest margin. Instead of minimizing the observed training error, the support vector regression (SVR) attempts to minimize the generalization error bound so as to achieve generalized performance. SVR can be used to train the hyper plane for predicting the data distribution. Regression function training is based on the joint parameters and the input feature vectors. LIBSVM (library for support vector machines)[10], a popular open source machine learning library, is applied to construct the regression functions for retrieving hand joint parameters from the feature vectors.
To train a regression function, we apply the training data with feature vectors and ground truth data. Feature vectors are obtained by our finger joint locating process and the ground truth data are collected from the 5DT (Fifth Dimension Technologies) Data Glove. The data glove returns fourteen parameters of which ten of them show the bending degrees of fingers, and the other four indicate the joint angles between fingers. In this paper we only use the first 10 parameters to train the regression functions. The ground truth data are used to validate the results of the proposed method.
6. Experimental Results
The random forest classifier is trained by 500 labeled training images, and the training samples of each tree are randomly selected around 500 pixels from each trainingimage. The maximum depth of each tree is set to 30 layers, and the random forest consists of 5 random decision trees. The regression functions are trained with 3000 pairs of training data. The experiments are conducted in the following environment: Quad-core Intel i5 3450 CPU, 8 GBs RAM, and NVIDIA GeForce GTX 660.

Table 1: Time consumption in each step.
6.1 Time Consumption
The computation time for each step is shown in Table 1. The system takes about 100 ms to render a hand model from a depth image. The most time consuming parts are per-pixel classification and feature point locating. If the per-pixel classification is optimized via a parallel implementation, the time consumption can be shorten significantly. Another step slowing down the hand pose estimation is the feature point locating. A possible solution is using a clustering algorithm instead of convolving with a Gaussian mask.
6.2 Reliability Evaluation
Fig. 5 demonstrates 10 sample frames with different hand gestures and their corresponding estimated results. The average values of ten parameters are illustrated in Fig. 6. The results of our approach using Kinect are compared with those of the ground truth data from 5DT Data Glove. The line on the bottom shows the average error of each joint. Since the maximum bending degrees of each finger joint are not the same (e.g., 90°for the first joint of the thumb vs. 120°for the second joint of the index finger), all joint parameters are normalized to the range [0, 1]. The average error of these testing frames is 0.115, which is acceptable for real-time hand parameter estimation.

Fig. 5. Sample frames with different hand gestures. Upper: RGB images; middle: detected feature joints; lower: estimated rendering results.

Fig. 5. Average hand parameters for the proposed method and the ground truth data.

Fig. 6. Influence of rotation on the proposed method.
6.3 Rotated Gestures Testing
We then demonstrate how the hand rotation influences the accuracy of hand pose estimation. The average error of the video stream is 0.174, which is larger than regular hand gestures. Fig. 7 shows that the minimum error occurs when rotation angle is 0°. As the rotation angle increases (decreases), the estimation accuracy decreases slightly, due to the out-plane rotation. Since the training set contains a few out-plane rotated cases, significant errors may emerge at high degree of rotation angle. The rotation angles inX-axis are calculated by the relative displacements of fingertips and the palm center.
6.4 Applied to Different Identities
The training images for the random forest classifier are all from the same identity. However, the joint detector with this random forest may obtain incorrect results for a different identity. Two individuals are recruited to test our system by wearing a data glove to collect the ground truth for evaluating the estimation accuracies. It turns out that the errors for distinct subjects are 0.194 and 0.192, respectively.
There are two possible reasons. First, different hand shapes cause errors for per-pixel classification and hence wrong feature vectors are obtained. This results in large estimation errors. Second, even for the same gesture, a data glove may capture different response values due to slight different hand shapes.
7. Conclusions
In this paper, we propose a method to estimate the hand joint parameters by joint detection and regression functions using Kinect. The proposed method retrieves continuous results within a short period of time, whereas the model-based method needs much more time to obtain its answers, and the appearance-based method gets discrete results though it works in real-time. Our approach works quite well if the experimental data of the participated subject are used for the training data. The extended work could be lifting the limitation and make the system user independent.
[1] J. Romero, H. Kjellstr?m, and D. Kragic, “Hands in action: Real-time 3D reconstruction of hands in interaction with objects,” inProc. of IEEE Int. Conf. on Robotics and Automation, 2010, pp. 458-463.
[2] S. Miyamoto, T. Matsuo, N. Shimada, and Y. Shirai,“Real-time and precise 3-D hand posture estimation based on classification tree trained with variations of appearances,” inProc. of the 21st Int. Conf. on Pattern Recognition, 2012, pp. 453-456.
[3] M. Gorce, N. Paragios, and D. J. Fleet, “Model-based hand tracking with texture, shading and self-occlusions,” inProc. of IEEE Computer Society Conf. on Computer Vision andPattern Recognition, 2008, pp. 1-8.
[4] I. Oikonomidis, N. Kyriazis, and A. A. Argyros, “Ef fi cient model-based 3D tracking of hand articulations using Kinect,” presented at British Machine Vision Conf., 2011.
[5] I. Oikonomidis, N. Kyriazis, and A. A. Argyros, “Markerless and efficient 26-DOF hand pose recovery,” inProc. of Asian Conf. on Computer Vision, 2010, pp. 744-757.
[6] H. Hamer, K. Schindler, E. Koller-Meier, and L. V. Gool,“Tracking a hand manipulating an object,” inProc. of IEEE Computer Society Conf. on Computer Vision andPattern Recognition, 2009, pp. 1475-1482.
[7] J. Shotton, A. Fitzgibbon, M. Cook, T. Sharp, M. Finocchio, R. Moore, A. Kipman, and A. Blake, “Real-time human pose recognition in parts from single depth images,” inProc. of IEEE Computer Society Conf. on Computer Vision and Pattern Recognition, 2011, pp. 1297-1304.
[8] M. Pó?rola and A. Wojciechowski, “Real-time hand pose estimation using classi fi ers,” inProc. of ICCVG, 2012, pp. 573-580.
[9] S. Theodoridis and K. Koutroumbas,Pattern Recognition, 3rd ed., Amsterdam: Elsevier/Academic Press, 2006.
[10] C.-C. Chung and L.-C. Jen, “LIBSVM: A library for support vector machines,”ACM Trans. on Intelligent Systems and Technology, vol. 2, no. 3, pp.1-27, 2011.

Chun-Ming Chang received the B.S. degree from National Cheng Kung University, Tainan in 1985 and the M.S. degree from National Tsing Hua University, Hsinchu in 1987, both in electrical engineering. He received the Ph.D. degree in electrical and computer engineering from University of Florida, Gainesville in 1997. From 1998 to 2002, Dr. Chang served as a senior technical staff member and a senior software engineer with two communication companies, respectively. He joined the faculty of Asia University, Taichung in 2002. His research interests include computer vision/image processing, video compression, virtual reality, computer networks, and robotics.

Che-Hao Chang received the B.S. and M.S. degrees from the Department of Electrical Engineering, National Tsing Hua University, Hsinchu in 2011 and 2013, respectively. He is current serving the military obligation in Army.

Chung-Lin Huang received his Ph.D. degree in electrical engineering from the University of Florida, Gainesville in 1987. He was a professor with the Electrical Engineering Department, National Tsing Hua University, Hsinchu. Since August 2011, he has been with the Department of Informatics and Multimedia, Asia University, Taichung. His research interests are in the area of image processing, computer vision, and visual communication.
Manuscript received December 15, 2013; revised March 15, 2014. This work was supported by NSC under Grand No. 101-2221-E-468-030.
C.-M. Chang is with the Department of Applied Informatics and Multimedia, Asia University, Taichung (Corresponding author e-mail: cmchang@ asia.edu.tw).
C.-L. Huang is with the Department of Applied Informatics and Multimedia, Asia University, Taichung (e-mail: huang.chunglin@ gmail.com).
C.-H. Chang is with the Department of Informatics and Multimedia, Asia University, Taichung (e-mail: bbb00437@ hotmail.com).
Digital Object Identifier: 10.3969/j.issn.1674-862X.2014.04.017
 Journal of Electronic Science and Technology2014年4期
Journal of Electronic Science and Technology2014年4期
- Journal of Electronic Science and Technology的其它文章
- Intrinsic Limits of Electron Mobility inModulation-Doped AlGaN/GaN 2D Electron Gas by Phonon Scattering
- Non-Linearity of Visual Sensitivity and Pursuit Velocity during Smooth Pursuit Eye Movements
- Automatic Vessel Segmentation on Retinal Images
- Family Competition Pheromone Genetic Algorithm for Comparative Genome Assembly
- Quantification of Cranial Asymmetry in Infants by Facial Feature Extraction
- Restricted-Faults Identification in Folded Hypercubes under the PMC Diagnostic Model