
Research on classification method of high myopic maculopathy based on retinal fundus images and optimized ALFA-Mix active learning algorithm
2023-07-20 10:30ShaoJunZhuHaoDongZhanMaoNianWuBoZhengBangQuanLiuShaoChongZhangWeiHuaYang
Shao-Jun Zhu, Hao-Dong Zhan, Mao-Nian Wu, Bo Zheng, Bang-Quan Liu,Shao-Chong Zhang, Wei-Hua Yang
1Huzhou University, School of Information Engineering,Huzhou 313000, Zhejiang Province, China
2Zhejiang Province Key Laboratory of Smart Management& Application of Modern Agricultural Resources, Huzhou University, Huzhou 313000, Zhejiang Province, China
3College of Digital Technology and Engineering, Ningbo University of Finance & Economics, Ningbo 315175, Zhejiang Province, China
4Shenzhen Eye Institute, Shenzhen Eye Hospital, Jinan University, Shenzhen 518048, Guangdong Province, China
Abstract● AlM: To conduct a classification study of high myopic maculopathy (HMM) using limited datasets, including tessellated fundus, diffuse chorioretinal atrophy, patchy chorioretinal atrophy, and macular atrophy, and minimize annotation costs, and to optimize the ALFA-Mix active learning algorithm and apply it to HMM classification.
● KEYWORDS: high myopic maculopathy; deep learning;active learning; image classification; ALFA-Mix algorithm
INTRODUCTION
High myopic maculopathy (HMM) is one of the main causes of blindness[1-2].The severity and progression rate of the disease are closely related to the degree and duration of myopia[3-4].With the continuous increase in the proportion of high myopia patients[5], the incidence of HMM is showing an upward trend year by year.Studies have shown that the risk of developing HMM increases significantly in patients with high myopia worldwide, with a probability ranging from 13.3% to 72.7%[6-7].For patients with HMM, there will be gradual vision loss, blurred central vision, distortion, and other symptoms,which greatly affect their daily life and work.Therefore,prevention and early detection are of great significance for the prevention and treatment of myopic maculopathy.In recent years, the application of artificial intelligence in the medical field has become one of the research hotspots[8].Many scholars have conducted in-depth research[9-16].And deep learning technology has gradually been applied to the prevention and early detection of HMM.Tanet al[17]developed a deep learning system based on XGboost and DenseNet to predict refractive error, high myopia, and HMM, achieving an area under curve (AUC) of 0.955 in the detection of HMM.Duet al[18]proposed a deep learning algorithm for classifying HMM, achieving an overall accuracy of 0.9208.These algorithms were also used to develop a pathological myopia research classification system by adding specific processing layers, which helped to screen pathological myopia.Raufet al[19]used convolutional neural networks (CNNs)to automatically detect pathological myopia, and the bestperforming CNN model achieved an AUC of 0.9845.Tanget al[20]developed a deep learning model based on ResNet50 and DeepLabV3+ using color fundus photographs to classify and segment HMM, achieving a classification accuracy of 0.937 and a segmentation F1 score of 0.95, effectively achieving the classification and monitoring of HMM progression.Sunet al[21]introduced a prior knowledge extraction module to extract prior knowledge to determine the rough lesion areas in fundus images, and integrated the obtained prior knowledge into the deep learning network, achieving an accuracy of 0.8921 in the five-classification experiment of HMM.To achieve good performance, deep learning training often requires a large amount of labeled dataset.Currently, the scale of HMM datasets is small, and annotators are often required to have high professional quality and experience, making annotation costs very high[22].Therefore, it is difficult to obtain large datasets for neural network learning.To achieve good results with a small amount of data, a series of methods and strategies have been proposed, among which one strategy is active learning[23].
Active learning can improve the performance of deep learning models when labeled data is limited.It dynamically selects the most valuable samples to be labeled during the deep learning training process, thereby reducing the amount and cost of manual labeling data.Currently, active learning can be roughly divided into three categories: uncertainty-based,diversity-based, and hybrid active learning algorithms[24].Uncertainty-based[25-26]active learning selects data that is difficult to distinguish in the model for labeling, thus achieving the ability to improve the model's performance.Uncertaintybased active learning methods are easy to adapt to various tasks, but they may not perform well in extremely imbalanced sample situations due to considering only the information content of the sample itself.At the same time, the selectors used in uncertainty-based sampling strategies are often shallow and may not work well on complex datasets.Diversitybased[27-28]query strategies select representative sample sets,which once selected can represent the entire dataset.However,a single query strategy may cause sampling bias and easily query outliers, making it difficult to select the most valuable sample set.Hybrid active learning algorithms[29-30]consider both uncertainty and diversity of samples, making it easier to select valuable samples.The development of active learning has also promoted its application in the medical field.Smitet al[31]combined active learning with meta-learning for selective annotation in medical image interpretation.The deep learning selector compared image embeddings obtained from pre-training to determine which images needed to be labeled and classified unlabeled images using cosine similarity.Shiet al[32]designed dual criteria for selecting informative samples.They proposed an active learning method for skin lesion analysis, which belongs to the category of post-labeling enhancement.The framework consists of sample selection and sample aggregation.In order to effectively use the selected samples, they designed an aggregation strategy by adding intra-class images in the pixel space, to capture more rich and clear features from these valuable but unclear samples.Zhanget al[22]used virtual adversarial perturbation and model density-aware entropy to find informative samples as labeling candidates and designed a balanced class selector to reduce redundancy in sample selection.This study builds upon the ALFA-Mix[33]active learning algorithm and proposes an improved version, called ALFAMix+, which is integrated with a deep learning model for automatic classification of HMM.The application of ALFAMix+ is expected to reduce annotation costs and facilitate the detection and screening of HMM.
MATERIALS AND METHODS
Data SourceThis study conducted experiments using an HMM dataset provided by a collaborating hospital.The study adhered to the principles of the Helsinki Declaration.The Medical Ethics Committee of Shenzhen Eye Hospital has approved this study with approval number 2022KYPJO45.To protect the privacy of the data providers, all data was deidentified prior to inclusion in the study.The specific details of the HMM dataset are shown in Table 1.
ALFA-Mix AlgorithmThe ALFA-Mix algorithm is a concise and effective active learning algorithm, which consists of two main stages.In the first stage, the algorithm utilizes the feature extraction module of a model to compute the average features for each labeled category and extract features from the unlabeled images.The unlabeled images are then mixed with the average features of each labeled category.Subsequently,predictions are made for both the unlabeled and mixed images,and samples with different prediction results are selected.In the second stage, the algorithm employs the K-means clustering algorithm to identify the most representative samples from the selected samples in the first stage, which are then submitted to experts for annotation.

Table 1 Dataset of high myopic maculopathy
ALFA-Mix+ AlgorithmIn the early stages of training, the ALFA-Mix algorithm may encounter a situation where a small number of selected samples can result in a significant number of inconsistent classification results before and after feature mixing.At this time, it is easy to ignore some samples that are difficult to distinguish but more helpful for improving the model performance during diversity selection.Therefore, in this study, we introduce the gradient norm to represent the selected samples.In the second stage, the algorithm modifies the sample selection process by computing gradients.Instead of selecting samples with significant differences, the algorithm now chooses samples that can produce diverse gradient vector directions.The sensitivity and confidence of the model towards the input data are represented by calculating the gradient magnitude of the model's loss function with respect to the output.If the gradient value is large, the sample is considered to have higher uncertainty.The gradient calculation formula is shown in Equation 1.
This study utilizes pseudo-labels predicted by the model for gradient computation.In the above equation,p(x) represents the probability distribution of pseudo-labels,q(x) represents the probability distribution predicted by the model, andWlastrepresents the parameters of the last layer of the model.When selecting representative samples using clustering algorithms,the gradient vectors of images will be used for clustering.Samples that can generate different gradient vector directions to update model parameters will be selected instead of samples with different features.The flowchart of the ALFA-Mix+algorithm is shown in Figure 1.
The steps of the ALFA-Mix+ algorithm are shown as follows:1) Extract the features of all training images using the feature extraction module of a deep model.
2) Calculate the average features of each labeled image category.
3) Interpolate the features of the unlabeled images with the labeled images' average features using the interpolation formula as shown in equation 2, where the interpolation ratioα∈ [0,1).
In the above equation,λclassrepresents the average feature of each class in step 2),λunlabelrepresents the feature of the unlabeled image, andλmixrepresents the mixed feature.For the selection ofα, in order to ensure the effectiveness of interpolation,αis chosen to maximize the loss of the interpolation point.The loss of the interpolation point is calculated by the formula in Equation 3).
In the equation above, ^yrepresents the pseudo-labels predicted by the current model, andfcis the classifier of the model.
4) Classify the mixed features obtained in step 3) and the features of unlabelled images using the classifier, and select the samples with inconsistent classification results.
5) Use gradients to represent the selected samples.
6) Use the Kmeans algorithm to annotate the selected m samples.
7) Add the labeled samples to the training set.
Repeatedly execute steps 1) to 7) until a stopping criterion is met.
Statistical AnalysisIn this study, active learning algorithms were combined with models in pairs for experiments.Each experiment was set to have 20 active learning rounds, and 100 images were selected for annotation in each round.The algorithm was evaluated by comparing ALFA-Mix+'s accuracy, sensitivity, specificity, Kappa value, and the number of rounds where it outperformed other algorithms.In the classification of HMM, accuracy, sensitivity, specificity, and Kappa values were used to evaluate each classification model.
RESULTS
Comparison Experiment of Active Learning AlgorithmsThis study employed five active learning algorithms, including ALFA-Mix, CoreSet[34], BALD[35], EntropySampling[36], and CDAL[37], as controls, and conducted experiments on four models: ResNet18, DenseNet169, VGG19, and AlexNet.Each experiment was set with 20 active learning rounds.The experimental results are shown in Figures 2-5, and Tables 2-6 displays the performance of each model under different amounts of data.Accuracy, sensitivity, specificity, and Kappa coefficient are commonly used evaluation metrics.A higher value for these metrics indicates better model performance.
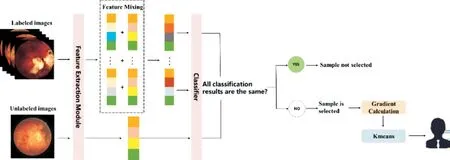
Figure 1 Flowchart of the ALFA-Mix+ algorithm.
Figure 2 displays the number of active learning rounds in which the accuracy results of ALFA-Mix+ exceeded those of the control algorithms within 20 rounds of active learning.
The accuracy results of different active learning algorithms on different models under different sample sizes are shown in Table 2.
Figure 3 displays the number of active learning rounds in which the sensitivity results of ALFA-Mix+ exceeded those of the control algorithms within 20 rounds of active learning.
The sensitivity results of different active learning algorithms on different models under different sample sizes are shown in Table 3.
Figure 4 displays the number of active learning rounds in which the specificity results of ALFA-Mix+ exceeded those of the control algorithms within 20 rounds of active learning.
The specificity results of different active learning algorithms on different models under different sample sizes are shown in Table 4.
Figure 5 shows the number of active learning rounds in which the Kappa values of ALFA-Mix+ exceeded those of the control algorithms within 20 rounds of active learning.
The Kappa value of different active learning algorithms on different models under different sample sizes are shown in Table 5.
According to the experimental results, using active learning algorithms can significantly improve the model performance,with good results achieved by using only 50% of the original dataset.In addition, increasing the amount of data can improve the model's accuracy, specificity, sensitivity, and Kappa value.However, as the amount of data increases, the growth rate of these indicators gradually slows down.This suggests that increasing the number of samples can improve model performance, but the growth rate may not increase significantly, and unnecessary labeling errors may sometimes occur.The ALFA-Mix+ proposed in this study compared with other active learning algorithms can achieve better results in most experiments when the same training samples are used,demonstrating the effectiveness of this research method.The confusion matrices obtained by each active learning algorithm on the four models are shown in Figures 6-8.We selected the best-performing rounds of each algorithm in their respective experiments for calculation.
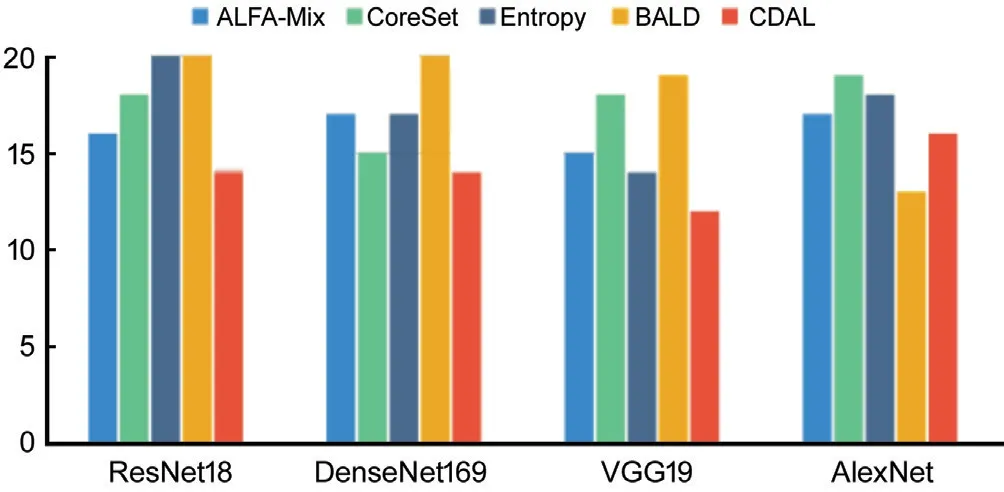
Figure 2 Number of active learning rounds in which ALFA-Mix+outperformed the corresponding control algorithm in terms of accuracy within 20 rounds of active learning.

Figure 3 Number of active learning rounds in which ALFA-Mix+outperformed the corresponding control algorithm in terms of sensitivity within 20 rounds of active learning.

Figure 4 Number of active learning rounds in which ALFA-Mix+outperformed the corresponding control algorithm in terms of specificity within 20 rounds of active learning.

Table 2 Accuracy results of each algorithm on ResNet18
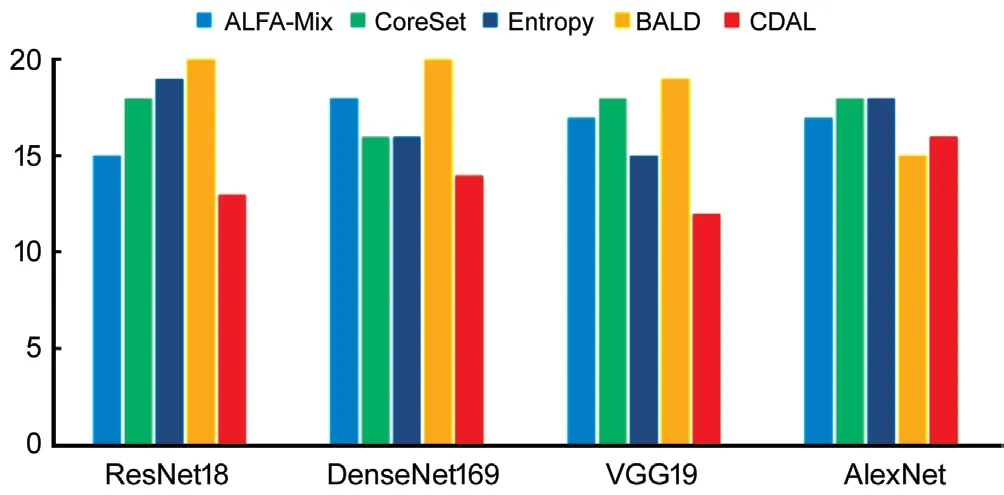
Figure 5 The number of times ALFA-Mix+ outperformed the control algorithm in terms of Kappa values within 20 rounds of active learning.
Experiment on HMM Classification Using ALFAMix+We implemented the classification of HMM using EfficientFormer[38], EfficientNetV2[39], VisionTransformer[40],DenseNet201[41], ResNet152[42], and SwinTransformer[43].Among these six models, DenseNet201, EfficientNetV2,and ResNet152 belong to deep convolutional neural networks, while EfficientFormer, VisionTransformer, and SwinTransformer use neural network structures based on attention mechanisms.We evaluated the performance of these six models using accuracy, sensitivity, specificity, and Kappa values.The performance of the 6 models on the HMM dataset is shown in Table 6.
Based on the comprehensive evaluation of various metrics, this study combined EfficientFormer with ALFA-Mix+ to achieve satisfactory classification results for HMM with a small amount of data.EfficientFormer is an efficient deep learning model composed of 4D convolutional neural network modules and 3D Transformer modules.
After combining with ALFA-Mix+, EfficientFormer achieved a classification accuracy of 0.8964, sensitivity of 0.8643,specificity of 0.9721, and Kappa value of 0.8537 on the dataset of HMM.It is evident that the performance of EfficientFormer was improved with the use of ALFA-Mix+ algorithm.The confusion matrix of EfficientFormer after combining with ALFA-Mix+ is shown in Figure 9.
DISCUSSION
The incidence of HMM has been increasing year by year.The annotation of HMM requires high accuracy and often requires annotators with high professional qualifications and experience.Therefore, the annotation process requires a great deal of cost.Using active learning algorithms can effectively select samples with high information content and representativeness in the dataset, which reduces annotation costs.
This study constructed an HMM classification model based on the ALFA-Mix+ algorithm.To fully demonstrate the effectiveness and advantages of the active learning algorithm,four classic classification models were used for experiments.As the number of data samples increased, the accuracy,specificity, sensitivity, and Kappa value of the model also gradually increased, but the rate of increase gradually slowed down.This indicates that as the number of samples increases,the number of new features learned by the model decreases,resulting in limited or no improvement in performance after adding samples.This situation may be because new samples do not contain too much new information or because the model has already learned and captured the potential features of the data well after a certain number of samples.Therefore, further increasing the sample size may have limited performance improvement on the model and may not significantly improve the classification results.The experimental results show that the ALFA-Mix+ algorithm can effectively select high-quality samples without sacrificing the final accuracy and reduceannotation costs.To classify HMM more accurately, this study finally used six models that performed well in other image classification tasks for experiments.From the experimental results, it can be seen that EfficientFormer achieved better performance on the HMM dataset and obtained more excellent results after applying the ALFA-Mix+ algorithm to this model.This further proves the effectiveness of the ALFA-Mix+algorithm.

Table 3 Sensitivity results of each algorithm on ResNet18

Table 4 Specificity results of each algorithm on ResNet18

Table 5 Kappa value results of various algorithms on ResNet18

Table 6 Performance of different models on the HMM dataset
By comparing the experimental results with other active learning algorithms, it can be clearly seen that the algorithm proposed in this study is significantly superior in performance to those that only consider uncertainty or diversity.This indicates that the proposed algorithm can better balance uncertainty and diversity when selecting samples, thereby improving classification accuracy.However, compared to algorithms that consider both, the method of selecting diverse samples in this study has some shortcomings, which results in not fully utilizing the diversity information of the samples.Therefore, in future research, more effective sample selection strategies will be designed to fully utilize the diversity information in the data and improve classification performance.Currently, some scholars have conducted research on the detection of HMM.Sogawaet al[44]applied deep learning technology to ophthalmic disease screening and proposed a new CNN classification model.The model performed well on classification accuracy, sensitivity, specificity, and AUC indicators, and the accuracy of diagnosis for different types of myopic eye diseases was above 77.9%, with an average accuracy of 88.9%.It can help prevent blindness, make disease screening more automated and efficient.Liet al[45]achieved higher classification accuracy than professional doctors in four disease classification tasks using Focal Loss and ImageData Generator techniques, and achieved automatic classification of OCT fundus macular scan images.This method has high accuracy and robustness and can effectively eliminate operator subjectivity.In addition, the study evaluated the model's performance using indicators such as the receiver operating characteristic (ROC) curve, demonstrating its high diagnostic accuracy and good clinical application prospects.Wanget al[46]used deep learning technology to screen high myopia patients with maculopathy through color fundus photographs, dividing all color fundus photographs into four categories: normal or mild snowflake fundus, severe snowflake fundus, early pathological myopia, and late pathological myopia.Its accuracy and recall AUC reached 0.922 and 0.781, respectively.The above experiments have achieved good results, but these methods all require a large amount of annotated dataset.This study combined active learning to achieve the classification of HMM, which improved classification accuracy with a small amount of annotated data, and reduced the cost and quantity of annotated data, providing convenience and support for the analysis and diagnosis of HMM.

Figure 6 Confusion matrices for ALFA-Mix+ (A) and ALFA-Mix (B) on AlexNet.

Figure 7 Confusion matrices for CoreSet (A) and EntropySampling (B) on AlexNet.
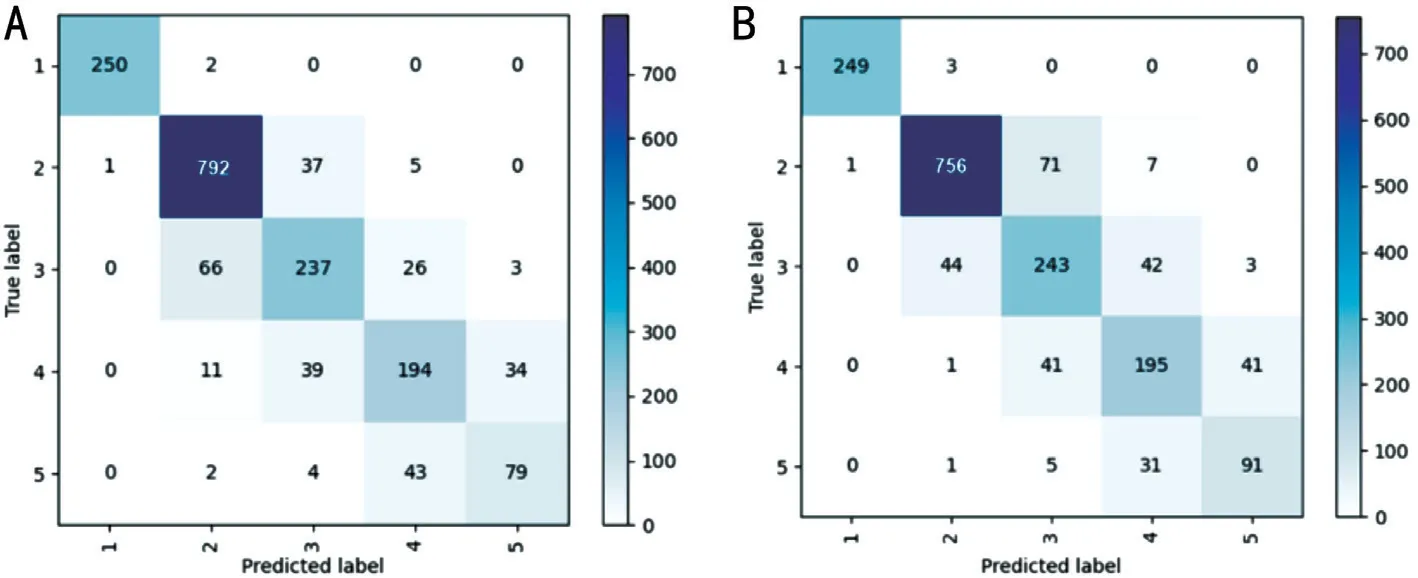
Figure 8 Confusion matrices for BALD (A) and CDAL (B) on AlexNet.

Figure 9 Confusion matrix of EfficientFormer after combining with ALFA-Mix+ algorithm.
Regarding the limitations and future research directions of the experiment, it is believed that the algorithm proposed in this study can still be optimized and improved in practical applications to further enhance its ability to select highquality samples.In addition, in order to further improve the practicality of the algorithm, issues such as scalability and computational efficiency need to be considered.In future research, image segmentation will also be included, and active learning algorithms will be applied to image segmentation.
In conclusion, this study proposes an ALFA-Mix+ active learning algorithm, which builds upon the ALFA-Mix algorithm by incorporating the images selected in the first stage of the gradient representation algorithm.This allows the algorithm to select samples in the second stage that can produce different gradient vector directions, taking into account the uncertainty and diversity of the selected samples.Experimental results showed that the proposed ALFA-Mix+algorithm can reduce the number of training samples required without sacrificing accuracy.Compared with other active learning algorithms, the ALFA-Mix+ algorithm performed better in more experiments with the same number of rounds,and could more effectively select valuable samples than other active learning algorithms.When combined with EfficientFormer in the task of HMM classification, ALFAMix+ algorithm improved the model performance and further demonstrated the effectiveness of the ALFA-Mix+ algorithm.
ACKNOWLEDGEMENTS
Authors’contributions:Zhu SJ, Wu MN, and Zheng B supervised this study.Zhan HD did the experiments.Zhang SC, Yang WH, and Liu BQ contributed to the conception and design of the work.
Foundations:Supported by the National Natural Science Foundation of China (No.61906066); the Zhejiang Provincial Philosophy and Social Science Planning Project(No.21NDJC021Z); Shenzhen Fund for Guangdong Provincial High-level Clinical Key Specialties (No.SZGSP014); Sanming Project of Medicine in Shenzhen (No.SZSM202011015);Shenzhen Science and Technology Planning Project (No.KCXFZ20211020163813019); the Natural Science Foundation of Ningbo City (No.202003N4072); the Postgraduate Research and Innovation Project of Huzhou University(No.2023KYCX52).
Conflicts of Interest: Zhu SJ,None;Zhan HD,None;Wu MN,None;Zheng B,None;Liu BQ,None;Zhang SC,None;Yang WH,None.
 International Journal of Ophthalmology2023年7期
International Journal of Ophthalmology2023年7期
- International Journal of Ophthalmology的其它文章
- Predicting visual acuity with machine learning in treated ocular trauma patients
- ldentification of hub genes for glaucoma: a study based on bioinformatics analysis and experimental verification
- Protective effect of ginsenoside Rg1 on 661W cells exposed to oxygen-glucose deprivation/reperfusion via keap1/nrf2 pathway
- Effects of endogenous dopamine induced by low concentration atropine eye drops on choroidal neovascularization in high myopia mice
- Differential analysis of aqueous humor cytokine levels in patients with macular edema secondary to diabetic retinopathy or retinal vein occlusion
- Subcutaneous pedicled propeller flap technique for microscopic reconstruction of eyelid defects