
Application Aware Topology Generation for Surface Wave Networks-on-Chip
2014-03-24 05:40ZhaoFuZhengBingHuChengGongWenMingPanandGuoBinLv
Zhao Fu, Zheng-Bing Hu, Cheng Gong, Wen-Ming Pan, and Guo-Bin Lv
Application Aware Topology Generation for Surface Wave Networks-on-Chip
Zhao Fu, Zheng-Bing Hu, Cheng Gong, Wen-Ming Pan, and Guo-Bin Lv
——The networks-on-chip (NoC) communication has an increasingly larger impact on the system power consumption and performance. Emerging technologies, like surface wave, are believed to have lower transmission latency and power consumption over the conventional wireless NoC. Therefore, this paper studies how to optimize the network performance and power consumption by giving the packet-switching fabric and traffic pattern of each application. Compared with the conventional method of wire-linked, which adds wireless transceivers by using the genetic algorithm (GA), the proposed maximal declining sorting algorithm (MDSA) can effectively reduce time consumption by as much as 20.4% to 35.6%. We also evaluate the power consumption and configuration time to prove the effective of the proposed algorithm.
Index Terms——Maximal declining sorting algorithm, networks-on-chip, surface wave, network performance.
1. Introduction
A large number of chip multiprocessors (CMPs) have been designed for different kinds of applications[1]nowadays, including scientific computing, big data, the Internet-based services[2], etc. One of the most important parts in CMP is its networks-on-chip (NoC)[3], which can provide efficient network communications for the processor cores. NoC is a communication paradigm that has emerged to tackle different on-chip challenges and satisfy different demands in terms of high performance and economicalinterconnect implementations, which can mostly determine the performance of a chip.
NoC in CMP is assumed to take a general purpose packet-switching fabric[4]where packets are transmitted through complex router pipelines in a hop-by-hop manner. Advances in the surface wave technique[5]open a door to handle the situation of too many hops in the network communication. The surface wave technique has been proved to be high performance, low latency, and less power consuption in NoC communication. With this emerging technology, time and power consumption can be greatly reduced and the throughput will become larger. Karkar[6]improved the surface wave technique to enhance its performance when one core communicates with many other cores. Fig. 1 shows the physical implementation of the surface wave technique.

Fig. 1. Surface wave interconnect communication channel with multi sub-channels, where the master node transmit through the shared surface to slave node(s)
In a mesh network, the packet-switching fabric is the basic for any communication between two different routers. And the packets only can go through two adjacent routers. The path where the packets go through is a hop. We can easily figure out that there are many hops between two different communication routers. If we can reduce the hops at the largest degree, the performance of the NoC will be the best.
In this paper, we propose a maximal declining sorting algorithm (MDSA) based on the declined hops. Benchmarks are carried out in the CMP simulator. Then the traffic volume of any communication pairs can be recorded. The following step is to calculate the hops between the communication pairs. Consequently, we can easily get theproduct of the hops and traffic volume. Wireless transceivers can be added based on the product. The larger the product, the more chances can be selected out, because the affect of wireless here is much stronger than anywhere else. As an example, there is a 3×3 common mesh network in Fig. 2. We randomly generate a communication graph in Fig. 3, which means we run an application on this 3×3 mesh network. Then we can generate the traffic volume of any communication pairs. As mentioned before, we will get the hops and product.

Fig. 2. Mesh network of 3×3.

Fig. 3. Communication graph.
The genetic algorithm (GA) is a widely used algorithm which can provide a new way for us to find the proper communication pairs that have a higher traffic volume. Depending on the results of GA and MDSA, we could get one of the possible topologies of the network mentioned in Fig. 3, respectively, which are shown in Fig. 4.
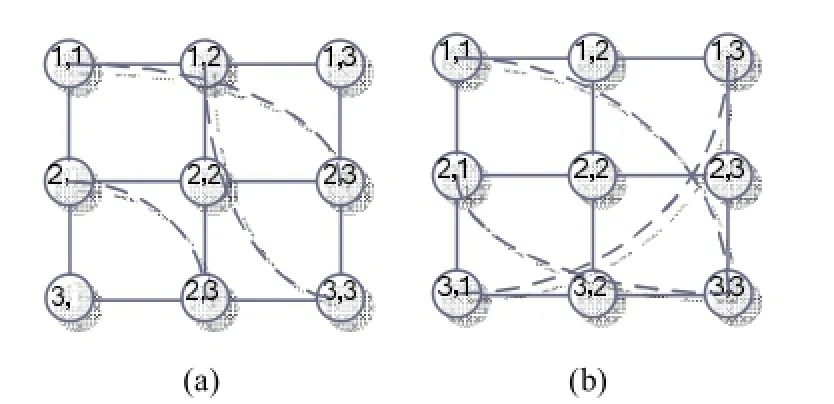
Fig. 4. Possible changed network topologies: (a) topology mimiced by GA and (b) topology modified by the proposed MDSA.
We can figure out the fact that the new proposed algorithm is more powerful than the previous conventional algorithm. Compared with the GA algorithm, the time consumption of MDSA is 24.7% less, and the power consumption also reduced.
The rest of the paper is arranged as follows. Section 2 introduces related research work. Section 3 describes the detailed problem. Section 4 presents the proposed MDSA and Section 5 describes the experiments which show the proposed algorithm is more effective. Finally, the conclusions are drawn in Section 6.
2. Related Work
Metal-based NoC just offers limited scalability with the relentless technology scaling especially in global network communications. It will cause more power consumption and lower throughput than the wireless link NoC. Image the scene that there are two communication cores which have a long distance between the two communication units. Common NoC in CMP is assumed to take packet-switching fabric for general purposes where packets are transmitted through complex router pipelines in a hop-by-hop manner. Then the communication here will take many hops rather than one hop by the wireless link. With more and more cores integrated into a single silicon chip, this situation will be even worse in the future.
On the other hand, emerging technologies[5], like the surface wave technique, have been proved to be low latency and high performance in network communications. With the surface wave, the throughput will be much higher and the average delay also can be greatly reduced. And some wonderful ideas[6]have been proposed to improve the performance of surface wave in NoC. It acts as a paradigm to tackle different on-chip challenges and satisfy different demands in terms of high performance and economical interconnect implementations.
To meet the scalability demand, this paper proposes a new hybrid architecture[1]-[6]combining the metal interconnect and Zenneck surface waves interconnects (SWIs) in NoC. The proposed architecture can evidently reduce the hop counts between any communication pairs, which will have better average network latency and higher throughput. Furthermore, SWI certainly can ensure the quality of the transmit signal while there are many wireless interconncetion simultaneously. The time consumption also can be greatly reduced by this new propose hybrid architecture.
3. Problem Formulation
Nowadays, much time and power has been spent on the network communication[8]when we run an application in a mobile phone, or some other electronic equipment. How to speed up the network communication in NoC so as to meet the demand of real-time applications brings in opportunities as well as challenges[9]. The target of our proposed algorithm is to mimic the network topology in a chip, then change the topology of the NoC in design time based on the algorithm. By running the same application on the optimized chip, we find that the communication time greatly is reduced and the performance of the chip is better.
Communication time in NoC is vitally important because it determines the network performance, and the network performance will determine the property of a chip. As we know, there are two key factors affecting thecommunication time[10]in NoC. They are the traffic volumes between two communication units and the hops from the source unit to the destination unit. The formulation of the communication time of running an application on a chip can be expressed as

wheresis the coordinate of the source in a rectangular plane coordinate system of the NoC anddmeans the destination. Each has two parameters which are the value inxaxis andyaxis.T(s,d) stands for the traffic volume between unitsand unitd, and hop(s,d) is the hops fromstod, andt0is the clock cycle that is needed for one byte data to finish one hop. The sum of each unit is the time that we need to run the application. Our target is to minimizef(s,d).
Then we can analyze the formulation step by step. The traffic volume of two units in a chip will stay the same once the application is defined. And the time cost for one byte data to go one hop is also a constant. Only the hops between two units can be changed by adding wireless transceivers to the source and destination. However, owing to the chip size and resources constraints, it is impossible to add transceivers to all units. The number of transceivers that can be added to a chip named “sum” and the number of transceivers that can be added to a unit called “mum” are strictly constrained. The constraints can be defined as

The sum also indicates the number of bridges can be built in one NoC. If there are too many transceivers in a unit, the performance of a chip may be lower, even the chip may power off because of the high temperature.
4. Proposed Algorithm
The architecture of the experiment CMP is described as follows. There are 64 cores on this mesh network CMP simulator, which also contains another 8 memory controllers in it. As the cache in cores have different access speeds, we divide the core into two parts: L1 and L2. L1 stands for a faster cache which is nearby the central processing unit (CPU), and L2 is a common cache. When we cannot fetch the data in L1 and get a L1 miss response, the core will access to L2 for the data. However, there also exsit L2 miss. Then the data fetch instruction may access to the memory controller for the data. It will not stop until getting a hit response or a memory controller miss response. There is a clear description in Fig. 5.
Consider the fact that the traffic volumes between two units keep the same once the application is defined. No matter the unit transfers the data packet to others or receives from others. We count the traffic volume of the source unit and destination unit. Then the traffic volume of the 64 L1s, 64 L2s, and 8 memory controllers can be obtained. So given a benchmark, we can quickly acquire the traffic volume of each router. When we run the benchmark in the CMP simulator, we can calculate the traffic volume of each router, which is shown in Fig. 6.

Fig. 5. Architecture of NoC.

Fig. 6. Number of parts in different level of traffic volume when we run the ferret benchmark in NoC.
The traffic volumes of L1 cache, L2 cache, and memory controler can be counted based on the experiment result before. Then the traffic volume between any two units of the overall 136 units can be counted. The busy routers in NoC can be expressed based on the different traffic volume in each pair of parts. In Fig. 7, those two units which have a higher workload will get a darker line between them. And the width of the line will be larger. According to the figure, the busier routers will be easily figured out. For those routers, the wireless link is the best option, which can reduce the communication time and poer consumption. A new topology of the NoC is generated depending on the traffic volume patterns of the benchmark.
And the time needed for one byte data to transfer between two adjacent routers is also a constant. So the only way to minimize the network communication time is to reduce the hops by adding wireless transceivers to the NoC. Once we set a pair of transceivers to the source unit and destination unit, the hops between them will be 1.

Fig. 7. Communication workload.
wherej(m,k) is used to record whether there is a wireless transceiver between the two units: 1 means yes and 0 means no, andmis the communication pair, kis a set of communication pairs. And fabs(s+s.j-d.i-d.j) means the hops between a communication pair, sourcesand destinationd. s.iis thexcoordinate of a source router,s.jis theycoordinate of a source router. Likewise,d.iandd.jis thexandycoordinates of destination.
The proposed new algorithm is based on the theory of maximally reducing the time if there is a pair of wireless transceivers between the two units. The algorithm can be described as

In this formulation, (s,d) is the set of the source and destination, time(s,d) records the reduced time, hop(s,d)-1 is the hops that can be reduced if there is a wireless transceivers between them.
Then we can sort the 2-dimension array in a descending order:

where sort(·) is the ranking function.
At last, we can select out the topnpairs of the source and destination under the constraint that each router can be linked with at mostmtransceivers and store the information in a set which is the solution that where to add transceivers is the most effective.

The conventional algorithm to mimic the topology is as follows. Given a mesh network, then the wireless transceivers can be added to the source and destination based on GA without any variation, where the son and its parent belong to the same units set. But the metal-based mesh NoC architecture can be modified by the surface wave based on the result here.
Compared with the proposed algorithm, the NoC proposed based on the experiment result of the conventional algorithm maybe a sub-optimal solution. The result is helpful but not the best. Maybe it can speed up the network communication and sometimes it may have a good effect. However, it will make no sense most of time. In the new proposed algorithm, we mimic the topology based on the theory of maximal declining. It directly points to the effect of wireless transceivers. This can be a well-defined way to optimize the topology. After the optimization, the performance of the chip will be better.
5. Implementation
There exist two same chips. The NoC in each chip has 64 cores and 8 memory controllers. We modify the topology of the NoC in two chips by two different algorithms: the conventional GA without any variation and the proposed MDSA, respectively. As mentioned before, wireless transceivers are added to the communication pairs. The parameters in the simulator when the applications are running are shown in Table 1.
Then the eleven benchmarks are carried out on the two new chips. The detailed information of each benchmark is shown in Table 2.
The experiment result is presented in Table 3. The column 1 is the name of benchmark. And the second one is the number of data packets in this network communication and the third one is the number of communication packets. MDSA and GA are the clock cycles needed to execute the benchmarks in the simulator by using MDSA and GA, respectively.

Table 1: Parameters used in the simulation

Table 2: Benchmarks

Table 3: Experimental results
The same eleven benchmarks are executed in the same simulator while the topologies of NoC are different. From Table 3, it can be seen that the time consumption of each benchmark can be reduced by 20.4% to 35.6%. As the time consumption for the network communication can be effectively reduced, the application can be run faster and more reliably. Then the power consumption of the chip can also decline. So the performance of the chip will be better to meet the demand of real-time applications.
6. Conclusions
This paper proposes the MDSA to optimize the network performance. From the experiment results, it can be seen that the proposed MDSA is more effective than the conventional GA without any variation method. By using the MDSA, the time consumption can be reduced by 20.4% to 35.6% and the power consumption also declines accordingly. The performance of the chip will also be better than the previous one. With more and more cores integrated into a chip, the time for network communication in NoC will be longer and longer. Then the proposed algorithm will play a more and more important role in solving the network communication task in NoC in the near future.
[1] A. Ganguly, S. Deb, and B. Belzer, “Scalable hybrid wireless network-on-chip architectures for multicore systems,”IEEE Trans. on Computers, vol. 60, no. 10, pp. 1485-1502, 2011.
[2] L. Pejman, “Scale-out processors,” inProc. of the 39th Annual Int. Symposium on Computer Architecture, New York, 2012, pp. 500-511.
[3] A. Ghiribaldi, D. Ludovici, F. Trivino, A. Strano, J. Flich, J. -L. S′anchez, F. Alfaro, M. Favalli, and D. Bertozzi, “A complete self-testing and self-configuring NoC infrastructure for cost-effective MPSoCs,”ACM Trans. on Embedded Computing Systems, vol. 12, no. 4, pp. 106:1-29, 2013.
[4] H. Bokhari, “DarkNoC: designing energy efficient network-on-chip with multi-VT cells for dark silicon,” inProc. of Design Automation Conf. 2014, San Francisco, 2014, pp. 354-360.
[5] A. Karkar, J. Turner, K. Tong, T. Mak, A. Yakovlev, and X. Fei, “Novel hybrid wire-surface wave interconnects for next generation networks-on-chip,”IET Computers & DigitalTechniques, vol. 7, no. 6, pp. 294-303, 2013.
[6] A. Karkar, “Hybrid wire-surface wave interconnects for one-to-many traffic handling in network-on-chip,” inProc. of Design, Automation and Test in Europe Conf. and Exhibition, Dresden, 2014, pp. 1-4.
[7] S. Lee, “ A scalable micro wireless interconnect structure for CMPs,” inProc. of the 15th Annual Int. Conf. on Mobile Computing and Networking, Beijing, 2009, pp. C.1.2-C.2.1.
[8] D. Ditomaso, A. Kodi, D. Matolak, S. Kaya, S. Laha, and W. Rayess, “Energy-efficient adaptive wireless NoCs architecture,” inProc. of the 7th IEEE/ACM Int. Symposium on Networks on Chip, Tempe, 2013, pp. 1-8.
[9] Y.-H. Jin and T. M. Pinkston, “PAIS: parallelism-aware interconnect scheduling in multicores,”ACM Trans. on Embedded Computing Systems, vol. 13, no. 3, pp. 108:1-21, 2014.
[10] A. E. Kiasari, Z. Hi Lu, and A. Jantsch, “An analytical latency model for networks-on-chip,”IEEE Trans. on Very Large Scale Integration Systems, vol. 21, no. 1, pp. 113-123, 2013.

Zhao Fu was born in Hubei, China in 1990. He received the B.S. degree from the China University of Geosciences (Wuhan) (CUG) in 2013. He is currently pursuing the M.S. degree in computer science with the same university. His research interests include networks-on-chip, computer architecture, and parallel computing.
Zheng-Bin Hu was born in Henan, China in 1991. He received the B.S. degree from CUG, Wuhan in 2013. He is currently pursuing the M.S. degree with the Department of Computer Technology, CUG. His research interests include networks-on-chip, computer architecture, and parallel computing.
Cheng Gong was born in Hubei, China in 1989. He received the B.S. degree from CUG, Wuhan in 2013. He is currently pursuing the M.S. degree with the Department of Computer Technology, CUG. His research interests include evolutionary algorithms, artificial neural networks, networks-on-chip, and chip multiprocessors.

Wen-Ming Pan was born in Guangdong, China in 1982. He received the B.S. and M.S. degrees in electronic engineering from Jinan University, Guangzhou in 2004 and 2007, respectively. He works as a research assistant with Guangzhou Institute of Advanced Technology, Chinese Academy of Sciences. He has been engaged in the FPGA design research for years. His research interests include networks-on-chip and parallel computing.
Guo-Bin Lv was born in Hubei, China in 1965. He received the B.S. degree from Xi’an Jiao Tong University (XJTU), Xi’an in 1987, the M.S. degree from CUG, Wuhan in 1996, and the Ph.D. degree from CUG, Wuhan in 2012. He is currently working as a professor with the Department of Network, CUG. His research interests include high performance computing and computer network.
Zheng-Bin Hu’s, Cheng Gong’s, and Guo-Bin Lv’s photographs are not available at the time of publication.
Manuscript received August 11, 2014; revised November 10, 2014. This work was supported by the National Natural Science Foundation of China under Grant No. 61376024 and No. 61306024, the Natural Science Foundation of Guangdong Province under Grant No. S2013040014366. and Basic Research Program of Shenzhen No. JCYJ20140417113430642 and JCYJ20140901003939020.
Z. Fu, Z.-B. Hu, and C. Gong are with the Department of Computer, China University of Geosciences (Wuhan), Wuhan 430074, China (e-mail: zhao.fu.unlv@gmail.com; tgbujm725vic@163.com; edoc1991@gmail. com)
W.-M. Pan is in Guangzhou Institute of Advanced Technology, China Academy of Sciences, Guangzhou, 511400, China (wm.pan@giat.ac.cn ).
G.-B. Lv is with the Department of Network, China University of Geosciences (Wuhan), Wuhan 430074, China (Corresponding author e-mail: gblv@cug.edu.cn)
Digital Object Identifier: 10.3969/j.issn.1674-862X.2014.04.005
 Journal of Electronic Science and Technology2014年4期
Journal of Electronic Science and Technology2014年4期
- Journal of Electronic Science and Technology的其它文章
- Study on Temperature Distribution of Specimens Tested on the Gleeble 3800 at Hot Forming Conditions
- Automatic Vessel Segmentation on Retinal Images
- Family Competition Pheromone Genetic Algorithm for Comparative Genome Assembly
- Quantification of Cranial Asymmetry in Infants by Facial Feature Extraction
- Intrinsic Limits of Electron Mobility inModulation-Doped AlGaN/GaN 2D Electron Gas by Phonon Scattering
- Real-Time Hand Motion Parameter Estimation with Feature Point Detection Using Kinect