
約束條件下測量誤差模型的統計推斷
2024-04-11 12:54王照良張旭陽
商丘師范學院學報 2024年3期
王照良,張旭陽
(河南理工大學 數學與信息科學學院,河南 焦作 454000)
在數據分析中,有些變量可能無法準確收集,如血壓,智力,肥胖等,在測量過程中會受到一定程度的影響,就會產生測量誤差.這導致了一類測量誤差(errors-in-variables)模型.記X∈p為真實模型中的解釋變量,Y∈p為響應變量,那么線性回歸模型有如下形式
Y=XTβ+ε,
(1)
其中β∈p為未知參數向量,ε是隨機誤差.在測量誤差模型中,解釋變量X是潛在變量,常常不能被直接觀測.本文考慮線性測量誤差或加性誤差模型,即
W=X+U,
(2)
其中變量W是可以直接觀測的,而U為零均值的測量誤差.假設測量誤差U與(Y,X)不相關,Cov(U)=∑u.為了模型的可識別性,進一步假設∑u已知.如果∑u未知,我們可以利用文獻 [1]中提出的重復測量技術,估計β是我們感興趣的事情.
正如文獻[2]中指出,如果忽略測量誤差而直接用W代替X,所得到的估計量和推斷可能有偏差和不一致.因此,調整測量誤差的存在對于準確描述真實解釋變量和感興趣的響應變量之間的關系很重要.測量誤差模型的研究可以追溯到文獻[3],文獻中提出了測量誤差線性模型參數的有效估計量.文獻[4]和[5]系統研究了測量誤差模型和數據分析,概述了存在測量誤差的情況下更現代的估計方法.當X,U,ε的分布已知時,可以使用似然方法估計參數,具體可以參見文獻 [6].實現這些似然方法通常需要使用數值方法近似計算,如高斯積分或蒙特卡羅積分.文獻[7]使用矩方法來估計線性測量誤差模型,考慮了基于三階矩和四階矩的參數估計,并發現這些估計量有很大的方差.關于測量誤差模型的其他研究成果可參見文獻 [8-11].
在某些情況下,一些關于回歸系數的先驗信息可以從外部樣本獲得.這些信息可能有不同的來源,如過去的經驗或實驗者與實驗的長期聯系,過去進行的類似實驗等.使用這些信息可以提高估算器的效率.在線性回歸分析的背景下,當這些信息以精確的線性約束的形式使用時,受約束的最小二乘估計量比普通最小二乘估計量更有效,如 [12].在許多重要的統計應用中,由于大量數據驅動的原因,模型(1)的參數分量可能會受到一些附加約束條件的約束.例如,[13]和 [14]中引入了對參數向量β的精確線性約束,構造了附加約束性條件下的修正拉格朗日乘子檢驗統計量.在本文中,我們假設參數向量β滿足以下線性約束:
Hβ=d,
(3)
其中H是一個k×p階的已知矩陣,rank(H)=k,d是一個k×1階的已知向量.[15]研究了基于約束條件(3)的模型(1)的估計.文獻中沒有考慮存在測量誤差的情況以及估計的有效性.當解釋變量X存在加性誤差時,[15]提出的方法會導致參數分量的估計是一個有偏估計量.為此,我們考慮基于約束條件(3)的模型(1) 和(2),并研究估計和檢驗問題.當H取到不同的矩陣時,我們可以得到不同的約束估計.實際上,參數的受約束估計起到了降維的作用.
本文在線性約束(3)的基礎上,研究了參數分量中有測量誤差(2) 存在的線性模型(1)的估計問題.我們提出了受約束的糾偏最小二乘估計量,并在一定的正則條件下建立了得到的估計量的漸近性質.最后通過模擬對所提出的方法進行了說明.
本文用M表示矩陣,A表示向量,記A?2=AAT,其中AT表示向量的轉置,矩陣類似.這一節提出了研究問題,第2節將闡述主要估計方法和提出估計量的漸近性質.第3節通過數值模擬研究了所提方法的有限樣本性質.第4節給出簡要結論.第5節給出相關理論證明.
1 估計方法和漸近性質
1.1 受約束的糾偏最小二乘法
假設(Y1;X1,W1),...,(Yn;Xn,Wn)是來自測量誤差線性模型
(4)
的一個獨立同分布的隨機樣本.在模型(4)中,X是潛在的不可觀測的p維解釋變量,W是p維可觀測變量,Y為響應變量,ε為模型誤差且期望為0,方差為σ2,U為測量誤差.本文假定E(U)=0和Cov(U)=∑u,且∑u已知.矩陣∑u可奇異,這意味著允許某些分量不存在測量誤差,未被污染觀測.
假設X可以被直接觀測到,即不存在測量誤差,則理論上β可通過最小化E‖Y-XTβ‖2得到,通過求導可得最優的估計方程為
E[X(Y-XTβ)]=0.
然而,測量誤差模型(4)中的X是不可觀測的,如果直接用W來替換X,最小化E‖Y-WTβ‖2,則有
E[W(Y-WTβ)]=-∑uβ≠0.
因此,直接用觀測變量W來替換潛在變量X,所得估計是有偏的,甚至是不相合的.注意到,
E[W(Y-WTβ)+∑uβ]=0,
于是,可通過最小化如下的偏差校正的目標函數
Qn(β)=‖Y-WTβ‖2-nβT∑uβ.
(5)
來估計未知參數β.式(5)右端的第二項-βT∑uβ是一個負的懲罰運算,其作用是削減由測量誤差帶來的影響.也就是說,當它是一個標量時,為了在絕對值中低估β,必須取更大的β來校正衰減,而不是進一步皺縮它接近于0.因此,它起一個校正的作用.
通過簡單計算,最小化(5)可以得到β的偏差校正估計量為
(6)
其中Y=(Y1,Y2,...,Yn)T,W=(W1,W2,...,Wn)T.
如果能夠獲得感興趣的回歸系數的先驗信息,則利用這些先驗信息可以提供更好的估計,如果我們忽略了先驗信息,可能會增加對數據誤讀的可能性.對模型(1)和(2),如果感興趣的參數β滿足精確的線性約束條件(3),本文提出通過最小化如下偏差校正的拉格朗日函數
F(β,λ)=(Y-Wβ)T(Y-Wβ)-nβT∑uβ+2λT(Hβ-d)
作為β的估計量.
利用函數極值的一階條件,對函數F(β,λ)分別關于β和λ計算偏導數,并且將結果分別設為零,即得到如下的估計方程
(7)
通過計算,可以得到方程(7)的解為
(8)

其中S=WTW-n∑u.
求未知參數β滿足約束條件(3)的一致估計量,還可以通過如下帶約束的極值問題
s.t.Hβ=d
1.2 漸近性質
為了得到估計量的漸近性質,我們首先給出下列正則條件.
C1.矩陣∑x=E(XXT)非奇異.
C2.隨機樣本(Y1;X1,W1),…,(Yn;Xn,Wn)獨立同分布.
C3.假定E(ε)=0,D(ε)=σ2且ε與X不相關.
C4.假定E(U)=0,且U與(X,Y,ε)不相關.
引理1假設條件C1-C4成立,當n→∞時,則
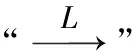
∑1=E{ε-UTβ}?2∑x+E{(UUT-n∑u)β}?2+σ2∑u
定理1假設條件C1-C4成立,當n→∞時,則
定理2假設條件C1-C4成立,當n→∞時,則
∑3=HT[HHT]-1H.
2 數值模擬
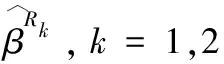
為實施模擬,利用模型(1)和(2)產生模擬數據.考慮p=4的情形,其中β=(1.5,2,1,1.5)T.顯然參數β滿足線性約束Hβ=0,其中矩陣H為
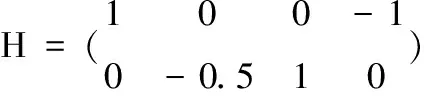
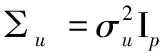
為了評估估計量的有限樣本性能,分別在樣本容量n=50,100,200下通過1000次重復模擬計算偏差(Bias),標準差(SD) 和均方誤差(MSE).模擬旨在研究不同樣本容量n,不同測量誤差水平∑u和X各分量之間不同相關性設置下的5種估計方法的表現.表1和表2分別展示了當∑x=Ip和∑x=(0.5|i-j|)1≤i,j≤p時的模擬結果.
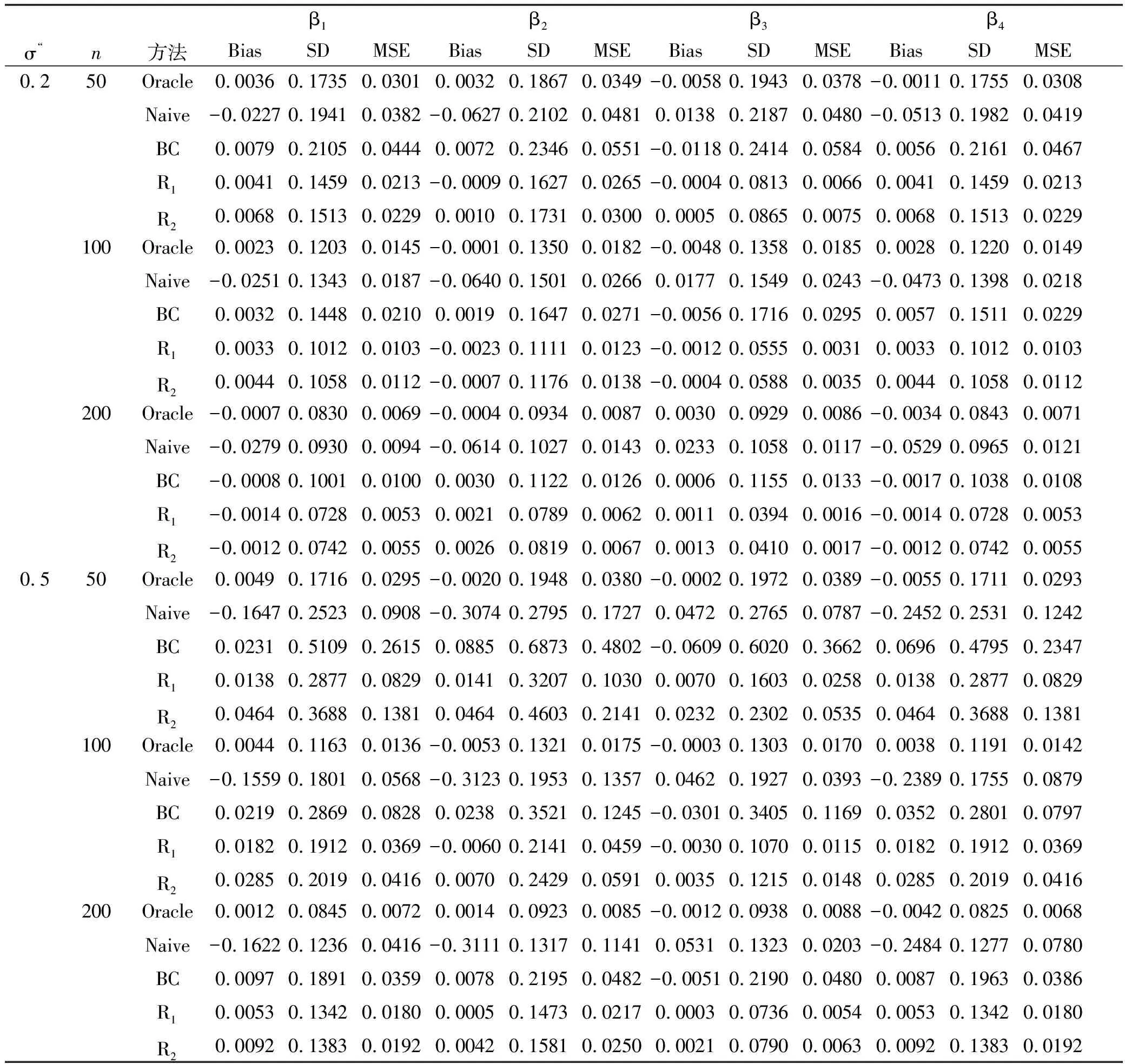
表2 當∑x=(0.5|i-j|)1≤i,j≤p時,5種估計方法的模擬結果
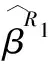
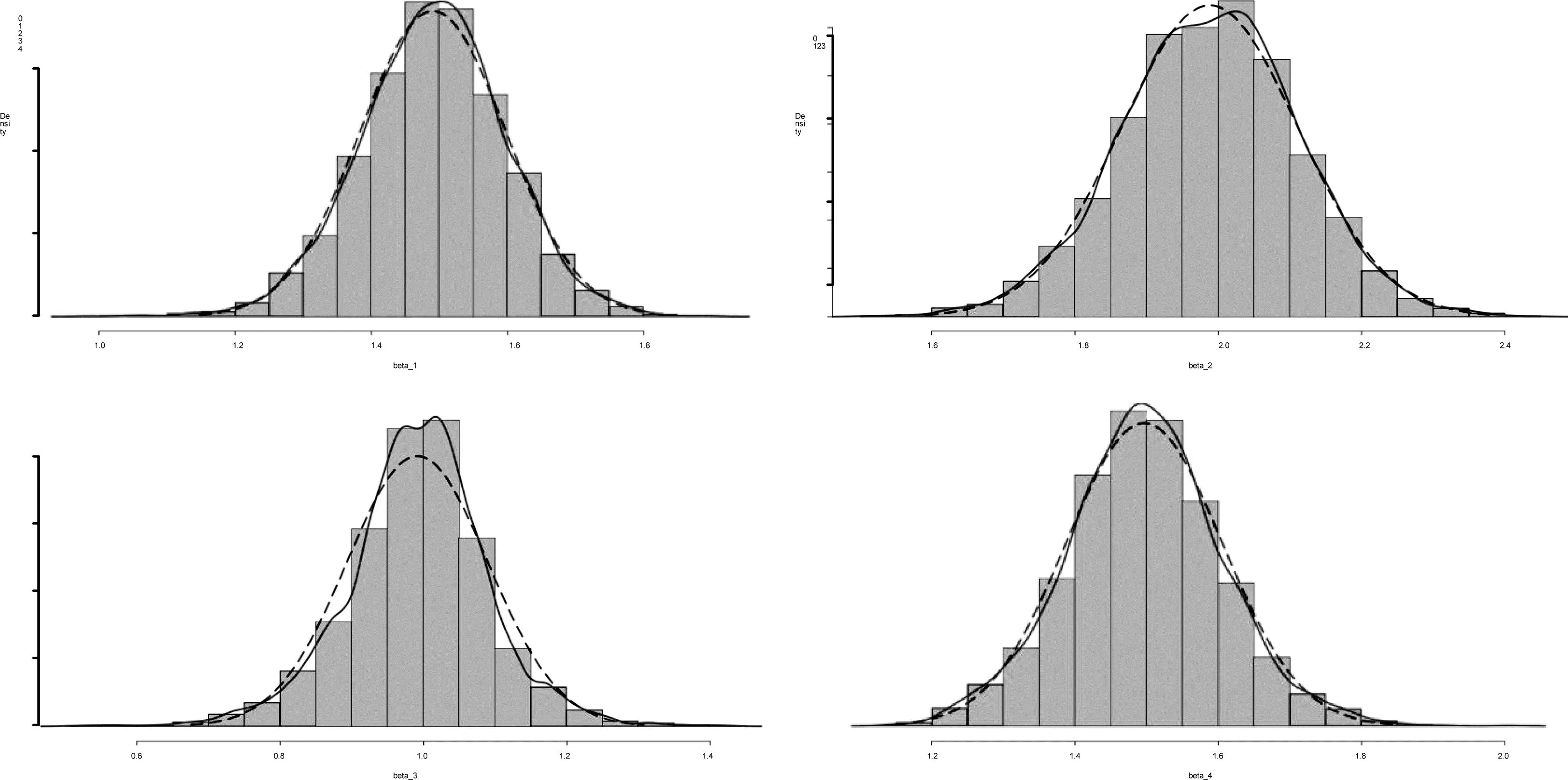
圖1 當∑x=Ip,σu=0.2,n=100時,基于1000次模擬計算估計量的直方圖及密度估計曲線
3 結 論
本文考慮了精確線性約束條件(3) 下測量誤差線性回歸模型的統計推斷問題.結合偏差校正最小二乘法和拉格朗日乘子法,對模型中的參數向量β提出了受約束的糾偏最小二乘估計方法.在一定的正則性條件下,證明了所提出的參估計量的漸近正態性.此外,通過MonteCarlo模擬研究了所提出方法的有限樣本性能.理論結果和模擬結果均表明所提出的估計量優于其他類型的估計量.
4 定理證明
4.1 引理1的證明
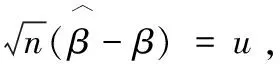
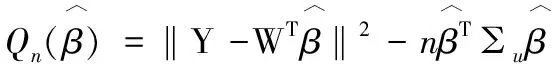
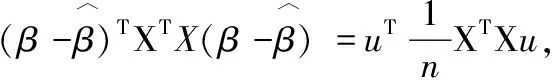


其中R是與u無關的項.
由ε,U和X的獨立性,以及中心極限定理,可知
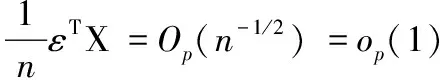
由條件C1和大數定律可得,
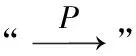
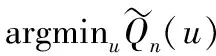
其中
由所給條件和大數定律可得,
此外,容易計算
E{XT(ε-Uβ)+UTε-(UTU-n∑u)β}=0.
根據中心極限定理,可得
∑1=E{XT(ε-UTβ)+UTε-(UUT-n∑u)β}?2=E{ε-UTβ}?2∑x+E{(UUT-n∑u)β}?2+σ2∑u
最后,根據Slutsky定理可知
引理1得證.
4.2 定理1的證明
證明 首先定義J=I-S-1HT[HS-1HT]-1H,其中
S=WTW-n∑u.
(9)
根據(8),簡單計算可知
其中J0=I-∑x-1HT[H∑x-1HT]-1H.
由Slutsky定理和引理1,可得
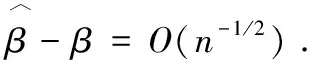
綜上,
定理1得證.
4.3 定理2的證明
類似于定理1的論證,可以完成定理2的證明.因此,我們省略了證明的細節.
猜你喜歡
電機與控制應用(2022年4期)2022-06-27
中學生數理化·八年級物理人教版(2021年12期)2021-12-31
應用數學(2020年2期)2020-06-24
Frontiers of Nursing(2018年1期)2018-05-21
現代營銷·學苑版(2016年12期)2017-01-23
電測與儀表(2015年18期)2015-04-12
電測與儀表(2015年6期)2015-04-09
雷達學報(2014年4期)2014-04-23
數學物理學報(2014年3期)2014-03-11
統計與決策(2012年4期)2012-07-24
